Taking Advantage of Deadman's Switch in Prometheus
When building systems, monitoring is extremely important to know the health of your system. Be it a car, with its basic engine light, a server that checks that a process is running, or a complicated distributed system that ensures things are happening within acceptable latencies. Monitoring is how you know your system is working as expected. Monitoring systems can range from seemingly simple, to very complex. The thing that they all have in common is that we rely on them to ensure our systems are working as expected. But then who or what monitors the monitoring system? How do you know the system you rely on to know the health of a system is - healthy?
Working with Kubernetes, and specifically prometheus, this question comes up from time to time.
“How do I know my monitoring system is working”.
This is a question anyone who implements a monitoring system should ask. Fortunately, there is a basic concept that can solve this problem. A Deadman’s switch
A Deadman’s switch, in the physical world, is fairly easy to understand. There is some system, that requires human interaction to function. If human interaction does not occur, the system ceases to function. For example, one that many people are probably familiar with is on a lawn mower. On many gas or electric lawn mowers, there is a lever or bar you must hold down for the engine to run. If you let go of the handle, including the bar you are holding down, the engine stops running. This is to prevent a runaway lawn mower causing damage or harm. Another example, which first introduced me to the concept is on trains. A train conductor on modern trains may be standing or sitting for a significant amount of time without needing to interact with the train. But, because we don’t want people literally sleeping on the job, trains will have a Deadman’s switch to ensure the conductor is awake and alert. This can take many forms but a common one is simply a light and a button. On a control panel a light turns on, the conductor must push the button, and the train keeps on going. If the conductor does not push the button the train will stop, assuming the conductor is incapacitated and cannot operate the train as needed.
In software this can work much in the same way, but in the case of systems monitoring, we don’t need to bring a human into the equation. Imagine for example, if you had an alerting system that sent out alerts at a regular interval, a heartbeat if you will. You also had some other system, outside of your primary system, that was listening for those alerts. Now imagine your outside system stopped receiving those alerts or heartbeats. It could then tell someone that it stopped receiving messages. This is the essence of the Deadman’s switch with prometheus, and how one can monitor one’s monitoring system.
Prometheus DeadMan’s Switch Alert Rule
Within prometheus it is trivial to create an expression that we can build a DeadMan’s switch from.
expr: vector(1)
That expression will always return true. Here is an alert that leverages the previous expression to create a Deadman’s switch alert.
- alert: DeadMansSwitch
annotations:
description: This is a DeadMansSwitch meant to ensure that the entire Alerting
pipeline is functional.
summary: Alerting DeadMansSwitch
expr: vector(1)
labels:
severity: none
This will send an alert off to your alertmanager with that description, summary and severity. Change as you see fit.
Ok, great. You have something that will send alerts all the time but now what? In order for this to be effective, something has to be recieving those alerts that can take action if an alert is not recieved. I created a usable implementation of a service that listens for alerts to show how this works that can be found here. Use whatever you like, and what works best for you. The rest of what I cover here does not assume you are using the tool I wrote because the concepts should apply universally.
Alert Manager Config
You’ve got your Deadman’s switch alert. Next, we need to setup alertmanager to know how to deal with these alerts.
The below example has the global config and other routes cut out, but I left the section headings in so you can see how this fits in the structure of an alertmanager config file.
global:
...
route:
...
routes:
- match:
alertname: DeadMansSwitch
receiver: 'cole'
group_wait: 0s
group_interval: 1m
repeat_interval: 50s
receivers:
- name: 'cole'
webhook_configs:
- url: 'http://192.168.2.66:8080/ping/bg8obqel0s1fdr02gtvg'
send_resolved: false
The important parts we need to add are the match rule under routes, a receiver, and the webhook config for that receiver.
Match rules
This defines how we are going to identify certain alerts, and once we find a match where do we send it.
alertnameis the name of the alert that will be sent with the alert payloadreceiver: which receiver to send this alert to- For
group_wait,group_intervalandrepeat_intervalyou don’t want to use the default values here because this alert is serving a different purpose. We don’t want to wait for them to be sent or hold back on repeats since we want it to go off at a consistent rate. group_wait: How long to initially wait to send a notification for a group of alerts. Allows waiting for an inhibiting alert to arrive or collect more initial alerts for the same group.group_interval: How long to wait before sending a notification about new alerts that are added to a group of alerts for which an initial notification has already been sentrepeat_interval: How long to wait before sending a notification again if it has already been sent successfully for an alert.
Receiver configuration
A receiver defines what to do with an alert that has been routed to it. In our case, we are going to be sending the alert payload to a remote webhook.
name a name for the receiver. This is the name that is referenced in the matching rules.
webhook_configs- this the notification integration that will be used to send out Deadman’s switch alerts to an outside system. This has a few parameters we are setting:- url the URL to the remote endpoint to send alert messages to
send_resolved: boolean true or false that controls whether you want to send a resolved message or not. For the case of the Deadman’s switch it will never resolve so we leave this set to false.
With that, your prometheus instance should be sending regular interval alerts to your alert manager. The alert manager is now configured to capture these alerts and route them to your external service, which will then signal if it stops receiving these alerts. See the below diagram for how this should be flowing
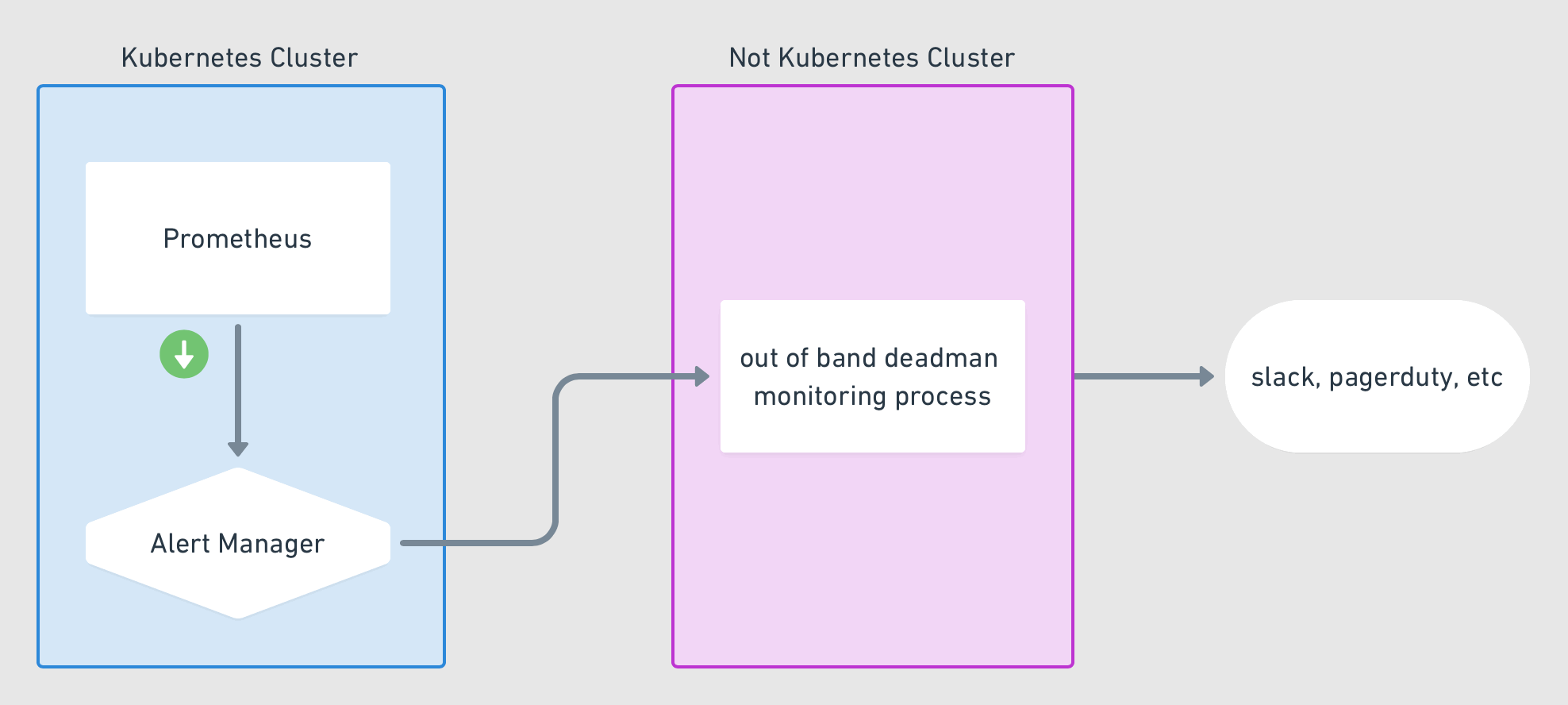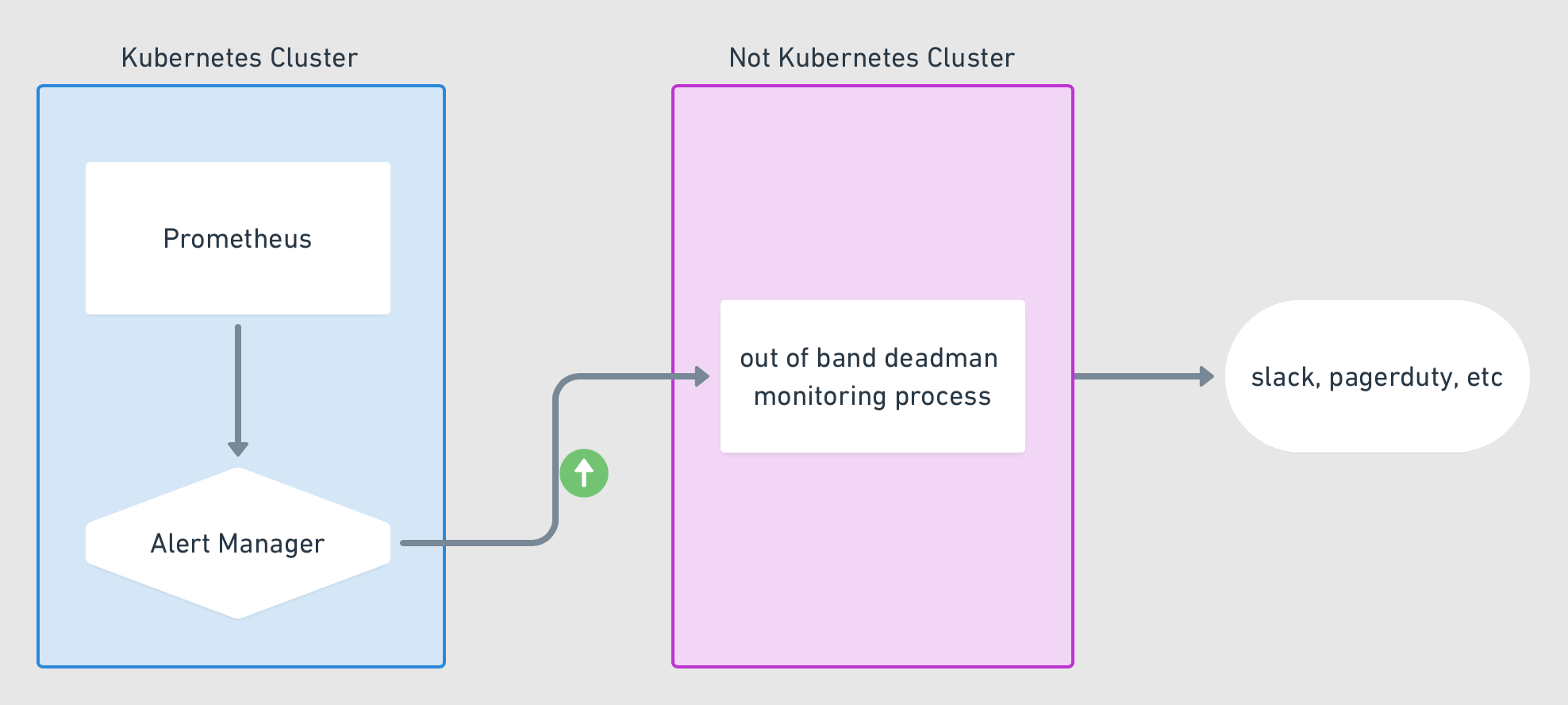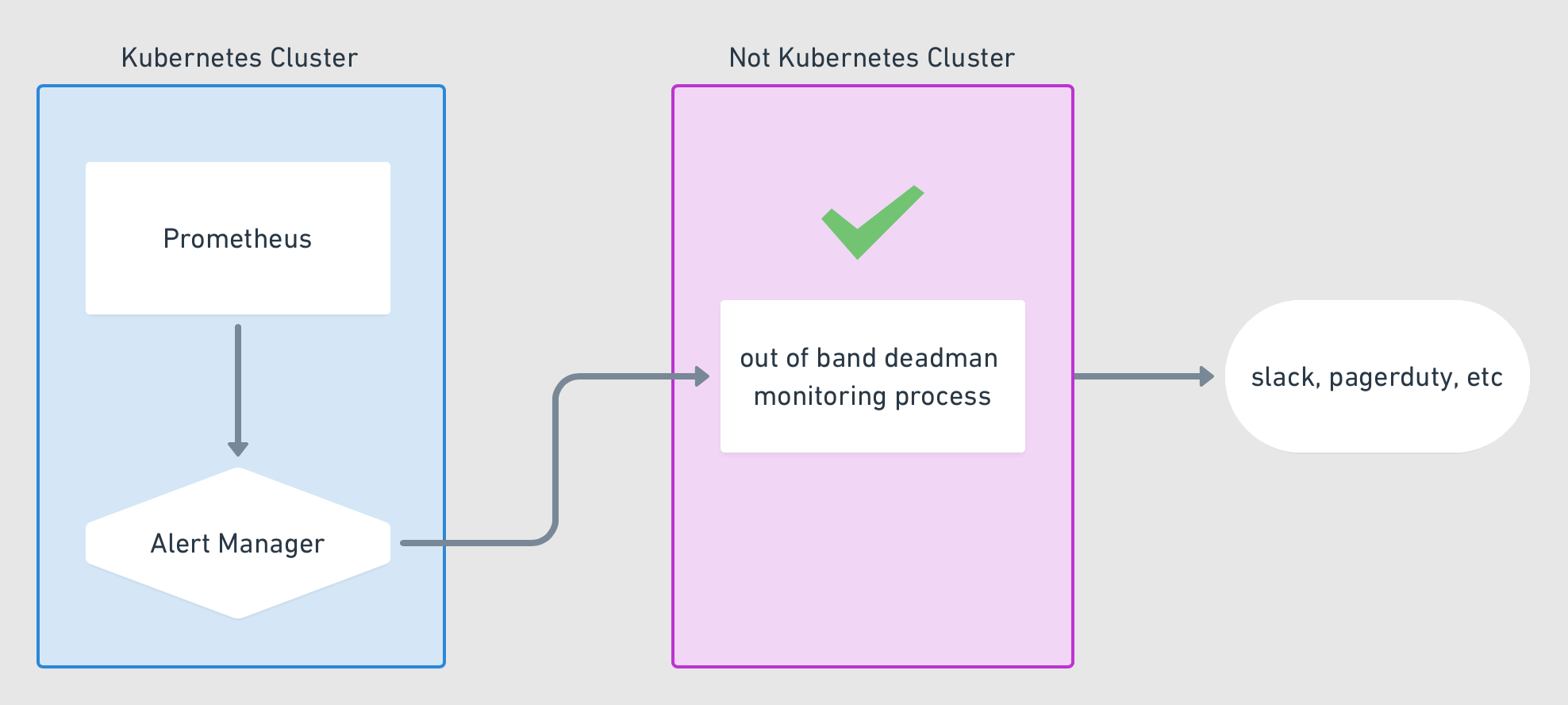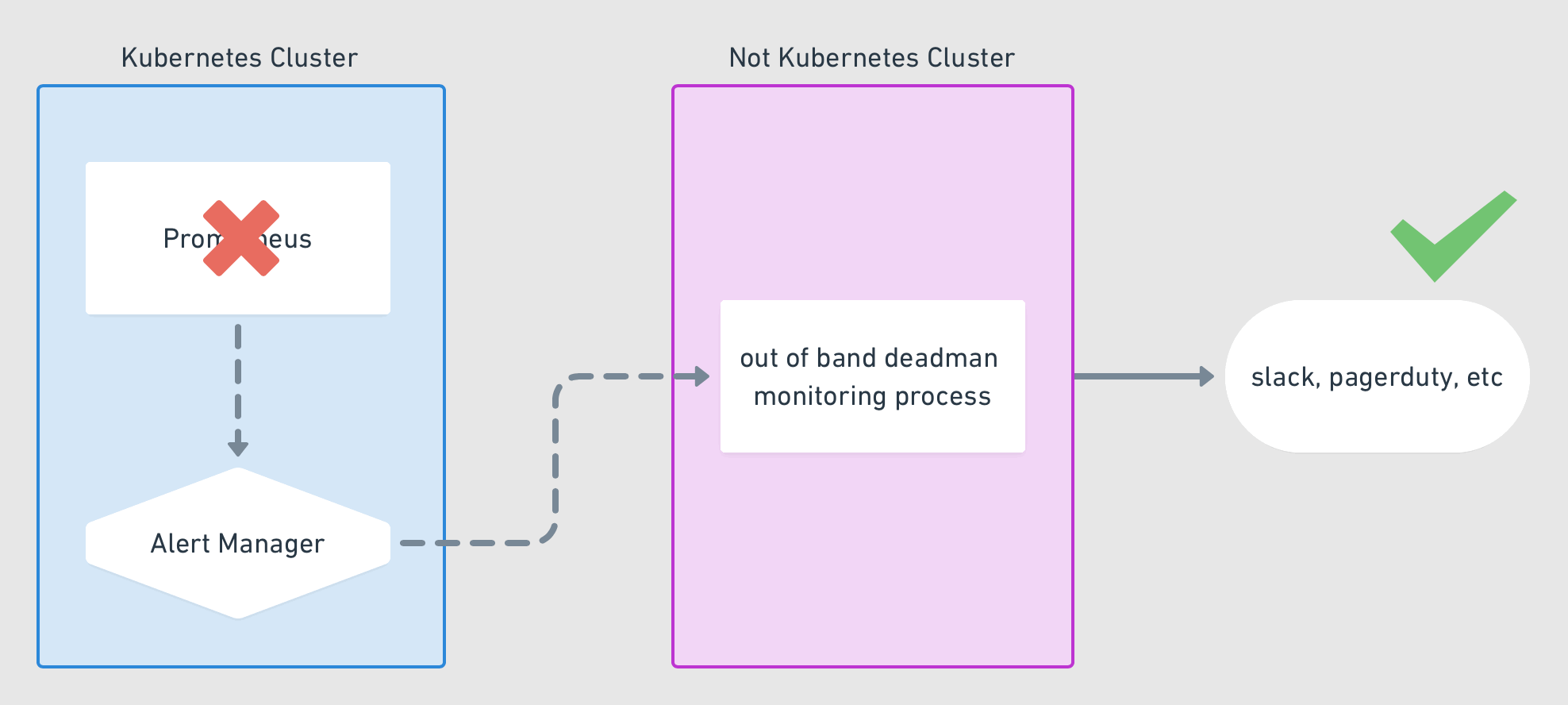
Monitoring systems are important to know things are working as you expect. But trust in your monitoring system is equally if not more important. Monitoring your monitoring system is a step in making that trust stronger. I’m sure some of you are thinking, but how do you monitor, your monitoring system monitor. Well, as they say, its turtles all the way down. One could keep building this forever but at some point, it needs end with something that is considered acceptable. This isn’t a silver bullet, but it is something that will solve for most cases.